
What does it take to get to the perfect user interface?
Technology advances at a rapid pace, and the time we spend interacting with machines is increasing quickly. The portal that we use to interact with machines is improving consistently and exponentially.
This blog discusses the state of the art in interface development and the future of our communication with this new form of intelligence. It is based on developments by Big Tech and data on user behavior gathered in past years.
Fundamentally, an interface must be able to optimize communication between humans and digital systems. By maximizing the amount of relevant information exchanged to achieve the user’s goal.
The perfect interface is immediately understood by the user and presents an experience that meets their needs in the shortest possible time.
An interface that optimally meets the user’s goal must provide a unique experience in each interaction. Thanks to the reduction in computational costs and the creation of new algorithms like Reinforcement Learning with Human Feedback, we are approaching this perfect interface faster than ever.
Creating an optimal communication portal depends on advancements in the following three components: intelligence, bandwidth, and alignment of objectives between artificial intelligence and humans.
Increasing Bandwidth
Bandwidth is a key component in the search for the perfect interaction between humans and digital systems. The amount of information that we can exchange with a system determines how useful the system gets. Currently the most common input has been text, limiting our capabilities of communication to the speed of our thumbs.
Text interfaces
The information transmission rate from an average adult to a computer is approximately 20 to 30 bits per second when typing on a phone, and 33 to 67 bits per second when typing on a computer. In contrast, a voice assistant can transmit up to 100 bits per second. The point of this comparison is to show how text cannot communicate as much information as other inputs and outputs.
Audio interfaces
It is important to take into consideration the nature of how humans process certain types of information, not only the amount of bits. Audio and video contain unique information that is lost in the text. The fluctuations in the tone communicate emotions and intentions that aren’t present in text. Video communicates non verbal information through body language.
Currently, voice interfaces are increasing in users. Devices such as Amazon’s Alexa, Google’s Assistant, and Apple’s Siri have proven to be pioneers in this field, the use of voice interface. Voice interfaces have extended into the automotive industry. Companies like BMW, Tesla, and Mercedes are adopting this technology to facilitate interaction while driving.
To gauge the magnitude of the adoption of multimodal interfaces, it is important to note that more than 100 million Amazon Alexas have been sold. It is available on 60,000 devices and connected to over 1 million. The market in 2024 for Smart Speakers is expected to exceed 30 billion dollars.
Sources: (Pop Sci, Globe Newswire, Venture Beat, Forbes, The Verge, Bloomberg, Statista, Science Direct, Insider, Tech Crunch, Global Market Insights).
According to Google in (2018), the adoption of audio and video is gradually increasing. 27% of the global population is using voice search on their cell phones, and 72% of people who have a voice-activated speaker use it as part of their daily routine.


Virtual Reality
New interfaces in VR and AR are also increasing the bandwidth by including the use of cameras and a diverse set of sensors in the headsets. They record visual and auditory information while providing an immersive experience as output.
The creation of these interfaces involves the development of sensors that gather data, creating rich datasets for machine learning algorithms. Multimodal data are already being implemented in the training of models such as GPT, which was previously text-only.
LLMs are incorporating these new data entries apart from text to have a more complete understanding of reality. Computing costs are decreasing and the technology to gather data is improving, making possible a reality with AGI.
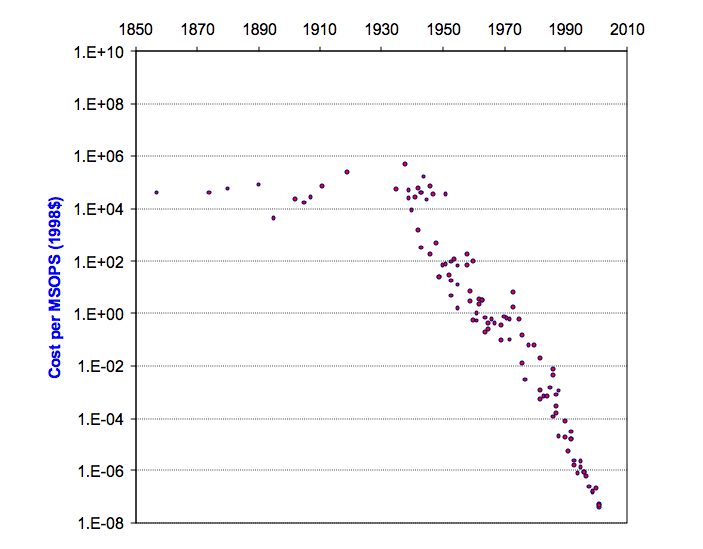
In the past, the data we had was about user behavior, demographics, and previous internet activity. Now, data about facial expressions, eye movement, and tone of voice is already available. The most powerful machine learning generative models will fall short compared to the ones that are trained with the data gathered from these new interfaces.
Brain Interfaces
It is clear that the new interfaces will enhance the intelligence of computational models, but what is the final frontier?
Using the fundamental principles of physics, the most direct way to communicate with machines is through our biological signals. Not only the sounds we emit and the movements we make but also the biochemical reactions in our brain.

Currently, smartwatches measure our heart rate, blood oxygen levels, and blood pressure. They are useful for preventing diseases by identifying patterns in the data; however, it is extremely important to emphasize the existence of a human being with a Neuralink implant (referred to as Telepathy) who is capable of playing chess merely by thinking. Neuralink is not the first organization to create brain-computer interfaces, however, it is a good example to show the great advancements humanity is making in this area. Elon Musk has said on X that he aims to increase the bandwidth between humans and computers by more than 1000X.
Increasing bandwidth is a promising solution to maintain control over artificial intelligence. Apart from increasing intelligence, from biology to synthetic, that is the first ingredient in the recipe to build the perfect interface.
The first ingredient to build the perfect interface is to increase communication. This is key to obtaining the next components, which are more intelligence and alignment between AI and human objectives.
Intelligent Interfaces
New interfaces are bringing more data as input. A great challenge for humanity is to build software capable of maximizing the use of this information to improve our communication and achieve our human goals in the best way possible.
Using only large amounts of text, highly intelligent models have been built. Using more types of data simultaneously to better understand the world is a very complex task, not only because of the infrastructure needed to clean and preprocess multimodal data but also because of the architectural design required to process different types of data efficiently and effectively—something that has taken biological organisms millions of years.
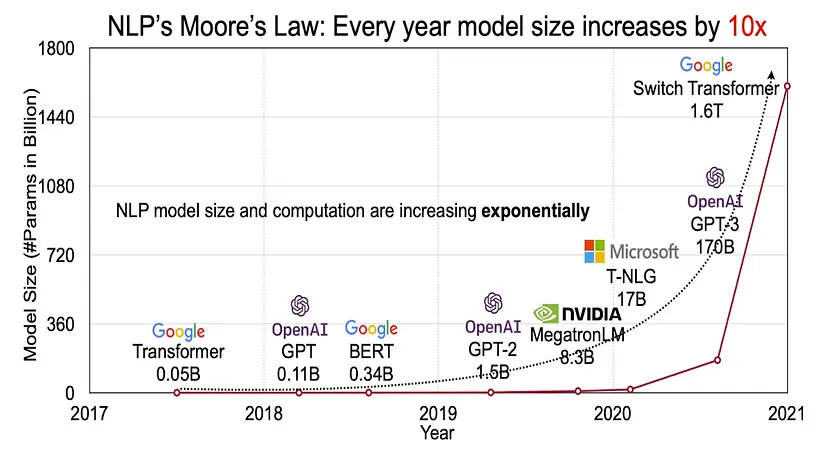
Multimodal machine learning models will allow for outputs in video and audio formats. Although GPT-4 is still text-based and allows for conversations, it does not directly handle audio and video. Since the algorithm is not open source, we cannot confirm whether it converts audio from interactions into text before responding, nor whether it uses convolutional neural networks to analyze voice volume fluctuations during conversations. However, given the quality of the product and the development team, it would not be unreasonable to think that they might be implementing these features.
Intelligent interfaces can be created from the visual and auditory data that is currently being collected. To respond with customized image and video for each situation, it modifies the visual, auditory, and textual information emitted by users in real time, based on the data generated throughout the entire history of interaction.
Increasing the intelligence of our interfaces will allow us to meet user objectives in the shortest amount of time possible, with a system capable of recognizing emotions and intentions without having to communicate them in the form of language.
Only one ingredient is missing, alignment: interfaces must be able to align with human objectives. It is essential for human survival that the goals of systems with this level of intelligence are aligned with ours.
These corrections will improve the clarity and accuracy of the text, making it more professional and easier to understand.
Obtaining alignment
Alignment entails the ability of machines to understand, anticipate, and adapt to human needs and behaviors. Ensuring that systems more intelligent than us strive to meet our needs is not a simple task and should not be taken for granted. Achieving specific alignment in the interface is necessary for intuitive and functional operation.
Alignment increases the satisfaction, creativity, and productivity of these systems. Good alignment reduces the learning curve of new technologies and minimizes communication errors between the user and the system.
The necessary advancements in artificial intelligence to improve alignment are made using user interaction data, allowing the prediction and adaptation of these interfaces to user preferences.
Examples of applications of good alignment include personalized learning in education, which can significantly increase interest and the speed at which humans learn. In the healthcare sector, diagnostic tools can be used to improve the processes of diagnosis and even intervention.
Currently, Deep Reinforcement Learning with Human Feedback (RLHF) is used, an algorithm that allows humans to provide feedback on machine decisions in the form of corrections, preferences, or by changing the rewards it receives to increase or decrease an action.
This allows the model to not only perform its function efficiently but also to align its actions with human objectives. Objective alignment is the final component of the recipe because despite the existence of extremely intelligent systems and rapid communication with them, it is useless if the goals of the machines are not aligned with meeting our human needs.
A future beyond our imagination
In conclusion, the future of interfaces will be determined by the increase in bandwidth that exists in the communication between humans and machines, in order to collect amounts of data previously unimaginable, and thus achieve artificial intelligence many orders of magnitude superior to human intelligence. To prevent this from getting out of control, it is necessary to continue developing algorithms that maintain alignment in the objectives of that superhuman intelligence.
Intelligent interfaces will allow us to meet our needs easily and quickly. The future of our interactions with machines will be defined by algorithms that not only process words but also process our voices and gestures, understanding our deepest desires and unexpressed needs. For this reason, alignment in objectives is fundamental to ensure that emerging technologies amplify our ability to solve complex problems, improve our quality of life, and surpass our boundaries of knowledge, instead of leaving our species behind.
On the other hand, rapidly growing technologies, such as brain-computer interfaces, promise a future where the line between human intention and computational response becomes more blurred. As this technology matures, we will be able to personalize interfaces to enhance the user experience, creating a new era in the relationship between humans and computers.
I conclude the article with a reminder: For a message to be understood exactly as the sender intends, the receiver has to be identical to the sender. The only way to achieve perfect communication is by turning the receiver into the sender.
References
Think with Google. (2020). Mobile usage and voice search statistics. https://www.thinkwithgoogle.com/
Yaguara. (2023). Voice search statistics: the future of search in 2023. https://www.yaguara.co/
Gminsights. (2023). Smart speaker market: growth trends, market share analysis, and forecast to 2028. https://www.linkedin.com/pulse/smart-speaker-market-insights-future-industry-sk12c
Datalab, Harish. (2022). Unveiling the power of large language models (LLM). https://medium.com/@mestiri.sa/unveiling-the-power-of-large-language-models-the-basics-d171c47f2223
Zhu, H., Zhao, Y., Li, M., Yang, B., & Liu, J. (2023). A Survey of Mobile Sensing for Human Activity Recognition. Sensors, 23(2), 220. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10543321/
Lecun, Y. (2024, March). Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI [Podcast]. Lex Fridman Podcast #416. https://www.youtube.com/watch?v=5t1vTLU7s40
Deja un comentario